如果你也害怕一个一个手动汇总
就和我一起鼓捣Python吧
时间飞逝, 三年一晃, 这就要大四毕业了🎓
时间过得真快, 忙完了手头事
赶着暑假的小尾巴, 开始着手解决这件事啦
也许开发程序着实让人觉得好很高大上, 触不可及
但其实并不是, 至少说简单的, 普通的程序稍微学学就可搞定
很多东西都是曲折着前进的
活到老, 学到老
我会较为详细的介绍开发的过程以及程序的使用方法, 作为一个记录, 也是一个指引
接触了你会发现很多有意思的细节(点了按钮发生了什么~), 也会愿意享受自动化的魅力
而且通过互联网, 互不认识的人相互学习和分享, 同时自己能作为这样的运动的一份子
科学技术是第一生产力~
它连接了你我, 也让很多事从容了起来
这里也做如下的声明:
此程序主要用于
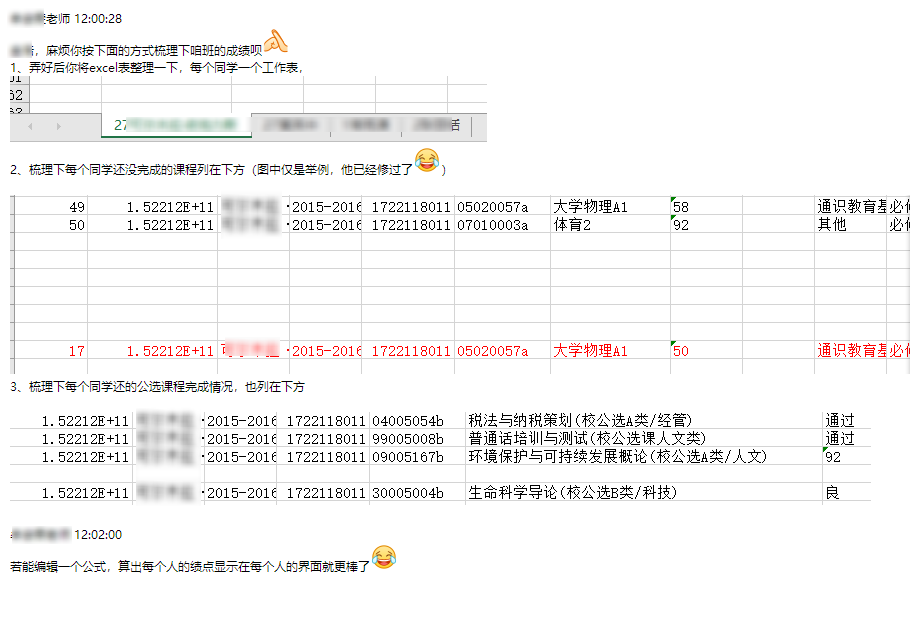
江苏科技大学2017级生物技术班的成绩统计使用.可以快速把单个同学的
各学期/学年/总学分绩点,公选课总分/选课,未/已通过课程等信息汇总在{name}-Summary.xlsx文件里.在此感谢17生物技术的各位同学们反馈的各种BUG.
在各位的帮助下, 得以让此程序拥有更宽广的眼界和胸怀, 而不再面对未知直接崩溃.
⚓️正如题图那样👩🏫
总之目前我们需要一款软件,可以实行如下功能:
- 获取未通过的课程
- 获取公选课信息
- 获取每位同学的绩点
- 以上信息按学生来汇总
明显的, 我熟悉的Python做这件事没有任何问题, 那我们开始搞吧
⚓️先探探路👣
我只熟悉这个随意的确定了编程语言后, 我们要确定整个程序的框架.
比如数据的结构/算法/工作流程…
⚓️打开浏览器开始吧💻
要确定这些我们肯定要先登录一下教务, 看看正常的登录教务的方式还有成绩获取的方式
链接在这里: 江苏科技大学综合教务管理系统-强智科技
打开映入眼帘的就是登录界面啦(还好没有验证码:happy: )

二话不说直接F12打开开发工具, 随便输入一个账号和密码, 点击登录

开发工具很明白的显示了当我们按下登录键后浏览器向服务器发送了一个post请求
这个请求带着我们的账号发给了在http://jwgl.just.edu.cn这个服务器的8080端口运行的/jsxsd/xk/目录里的LoginToXk, 不过这里我们不搞更复杂的啦, 反正把账号发给他就行了
同样的, 通过点击按钮后查看开发工具里网络, 得到按了按钮后浏览器发出的数据请求
我们就可以获取其他的获取信息的post请求啦:
成绩查询:
- 请求 URL: http://jwgl.just.edu.cn:8080/jsxsd/kscj/cjcx_list
- post表单: kksj=&kcxz=&kcmc=&xsfs=all # kksj指开课时间 kcxz指开课学期 …
学期理论课表:
- 请求 URL: http://jwgl.just.edu.cn:8080/jsxsd/xskb/xskb_list.do
- 请求方法: GET #这个
get方法不需要传数据 只需要请求这个链接就行可以得到数据了
个人学业清查:
- 请求 URL: http://jwgl.just.edu.cn:8080/jsxsd/view/pyfa/pyfazd_grxyqc.jsp
- 请求方法: GET
…
有了技术, 剩下的就是体力活了👷 , 要请求什么, 全部搞一遍然后列到文档里备用就行了
然后就是请求网页时我们要用的方式了, 当然是用最好用的 Requests
它就可以构建post请求, 这样可以帮助我们登录教务系统
也可以构建get请求, 直接获取其他的数据, 就像这样:
1 | jwxt_session = session() # 创建一个名为jwxt_session的可以持续访问网页的session对象 |
得到的数据从某种意义上说, 不是人喜欢读的, 那我们还要专门处理这些数据的手段
bs4是一个强大的处理HTML网页数据的第三方软件包, 可以用它来获取页面的数据
比如这样的
1 | main_page = login_jwxt(account, password) # 调用登录网页的函数后得到的数据后传给main_page |
如果是以表格的形式出现的(也就是<\table>标签包裹的数据), 本来也是可以用bs4直接获取然后存入设计好的变量里等待处理的. 不过天降猛男, Pandas就很在行🚀 , 人家有 read_html() 方法~
__pandas.read_html(*args, **kwargs) __
Read HTML tables into a list of DataFrame objects.
Parameters
io [str, path object or file-like object] A URL, a file-like object, or a raw string containing
HTML. Note that lxml only accepts the http, ftp and file url protocols. If you have a URL
that starts with ‘https’ you might try removing the ‘s’.资料来源: pandas : powerful Python data analysis toolkit Release 1.1.2
如上, 传入html 的原始数据(raw string containing HTML), 它就可以返回数据帧(DataFrame)
这就很妙了, 因为得到数据数据只是第一步, 处理数据也是个麻烦事
而Pandas就是处理数据的能手
这样直接将<table>转换成数据帧(DataFrame)岂不美哉
(数据帧是Pandas的基本数据结构, 这样就可以直接用它处理数据了)
处理数据的问题可以预见基本解决了, Pandas可以满足的
那还剩下汇总导出的问题, 二话不说直接Bing一下(欢迎大家来用Bing)
得知有一个叫openpyxl可以操纵Excel, 而且也想起来之前我的群里有樊同学传过这个库的文档
这里找了个中文的文档. 一通阅读, 基本确定可以满足我的要求
可以创建Excel填充数据, 也可以修改样式
几大基本的问题都解决了,汇总一下成果吧
⚓️技术路线🔗
采用 Requests 登录教务系统 并获取个人信息和成绩源数据
使用 bs4 按照获取的网页的特定内容
使用 Pandas 获取成绩页面的<table>标签并转为DataFrame
按照学校的计分规则自编计算绩点和筛选成绩的函数[^ 函数精度]
使用 openpyxl 按照设计的样式和计算的结果生成 Summary 文件
⚓️RequestsYourScore1.0🙄
开发自然要有工具, 这里我直接使用Jupyter作为开发这款程序的平台
得益于内嵌的IPython, Jupyter可以运行Python
同时可以按步调试, 返回程序执行之前的状态
内容可以以比较美观的形式显示在浏览器上
⚓️特性 Features
- 命令行式界面
- 输入账号密码自动生成
Summary文件 - 可将此项目做库导入使用,包含有如下实用函数:
- table_xls(table_df, file_name) : 将得到的DF(DataFrame)表按照输入的文件名导出xls文件
- public_elective(file_name=‘’): 返回
公选课DF, 如果导入文件名直接输出xls - theory_schedule(file_name = ‘’): 返回
学期理论课表,~ - now_no_pass(): 返回尚
未通过的课程 - training_program(file_name = ‘’): 返回
培养方案,~ - add_academic_credits(table_df, ignore=True):在传入的表的最右侧加一列
学分绩点,并返回 修改过的表/表格内的平均绩点/总学分;ignore参数为在计算平均绩点和总学分的时候是否忽略公选课,体育课和补考通过的课程 - point_summary(): 返回绩点字典,包含 总平均绩点/各学年学期绩点
- …
由于是特定班级使用所以有一定的局限性
- 公选课的识别可能只覆盖了自己班内部的,不够全面
- 自动化的
Summary文件只统计了需要的几个课程信息不一定是你需要的
⚓️使用我吧
你可以直接使用打包好的exe可执行文件
这里下载 下载请点我 , 双击即可运行 Window 系统下直接运行.
你也可以直接下载源代码使用
安装Python 或者是 Anaconda 使用这个源代码
在终端比如 cmd 里,进入该项目文件夹后,使用这个命令:
pip install -r requirements.txt
这样就安装了需要的库, 然后运行:
python JUSTScoreSummary.py
⚓️小工具
在该仓库的 othertool 里有些小工具
classloop.py: 可以将此py文件放在主要代码的同一目录, 然后在同目录自己创建一个account.txt文件, 里面按照学号 密码的形式一行放一位同学的账号, 启动程序后, 就可以按顺序生成不同同学的Summary文件了.班级汇总宏(使用我合并文档).xlsm: 得到的Summary文件使用这个文档里的宏来合并.
⚓️样例
最后生成的summary文件为xlsx文件, 一个同学一个同名工作表(sheet)
而且如果有未通过的课程, 工作表的标签颜色将变成红色:

以下是某位同学的成绩, 这里作为最终的summary文件的样例列出:
